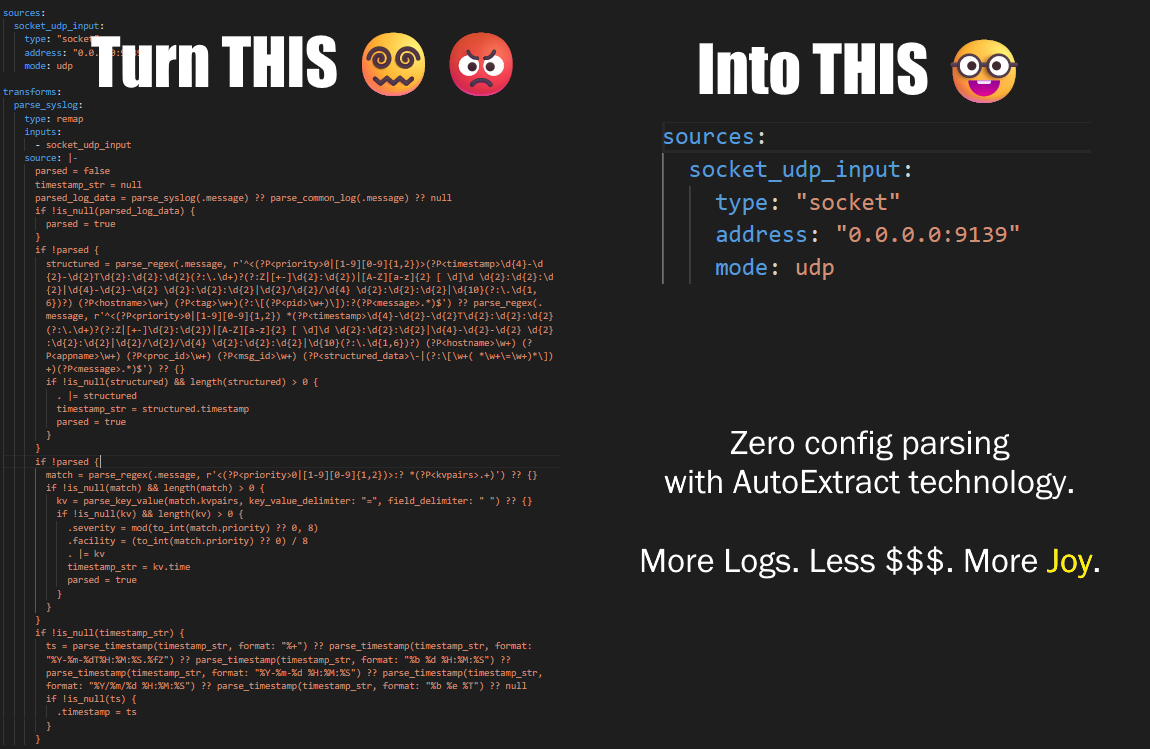
Schemaless
Ingestion is "point and shoot" — fields don't have to be configured, just send data. Capture complex JSON data with each log event. No field limits.
AutoExtract
Auto-extract semi-structured and JSON data from plain text. Auto-detect field types. Auto-extract IP addresses, timestamps, and bracketed values.
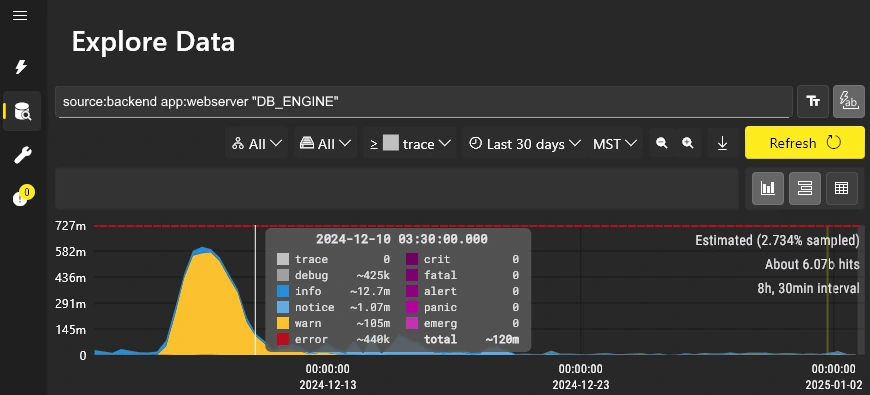
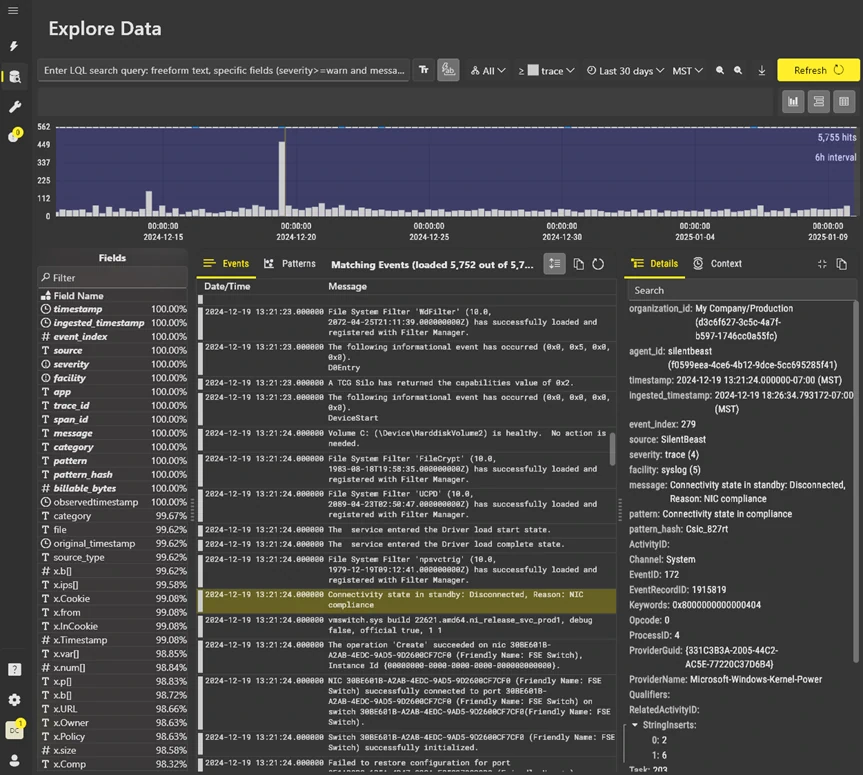
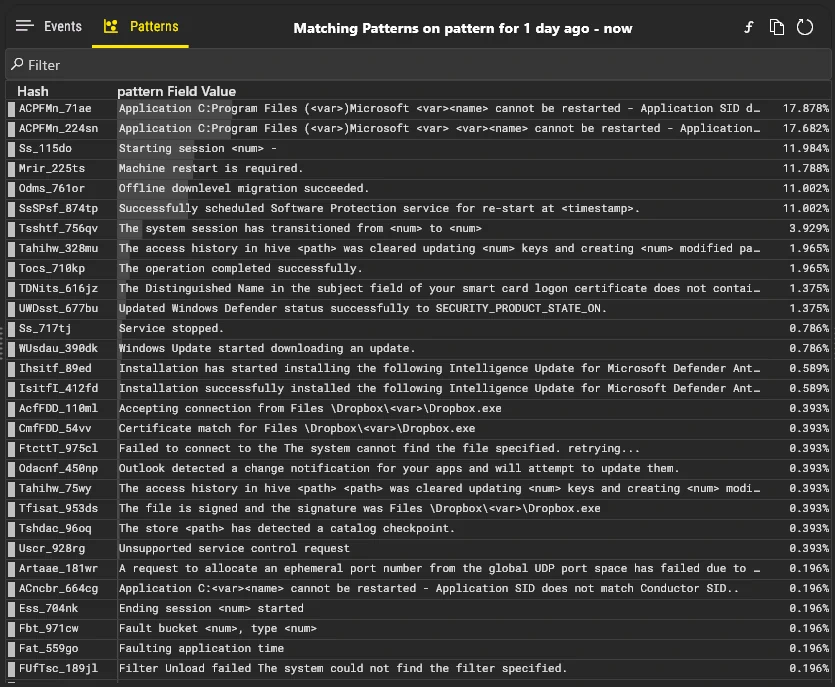
Visual Data Exploration
Visualize patterns across billions of events.
Instant zoom-in, filter, search, and export.
Easily sift through huge query results.

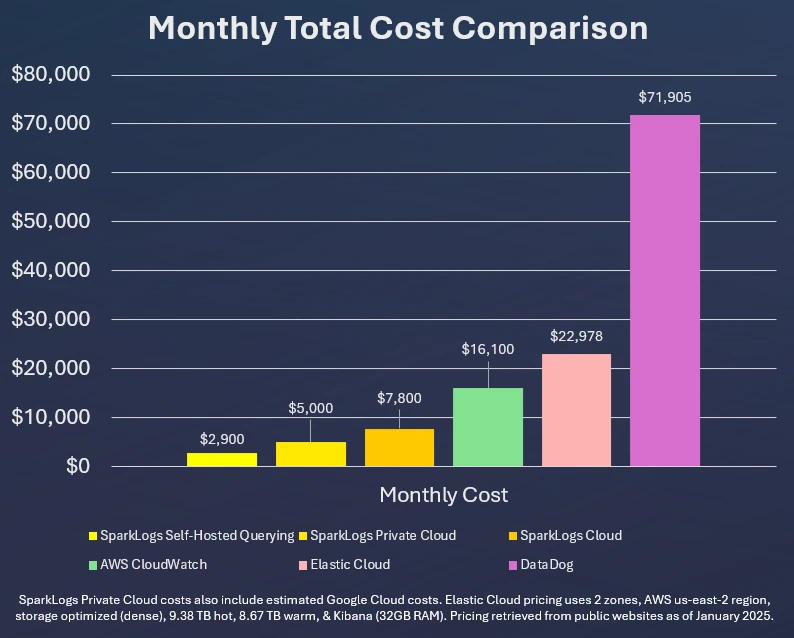
Petabyte Scale
Fully managed in our cloud.
Always on, infinitely scalable.
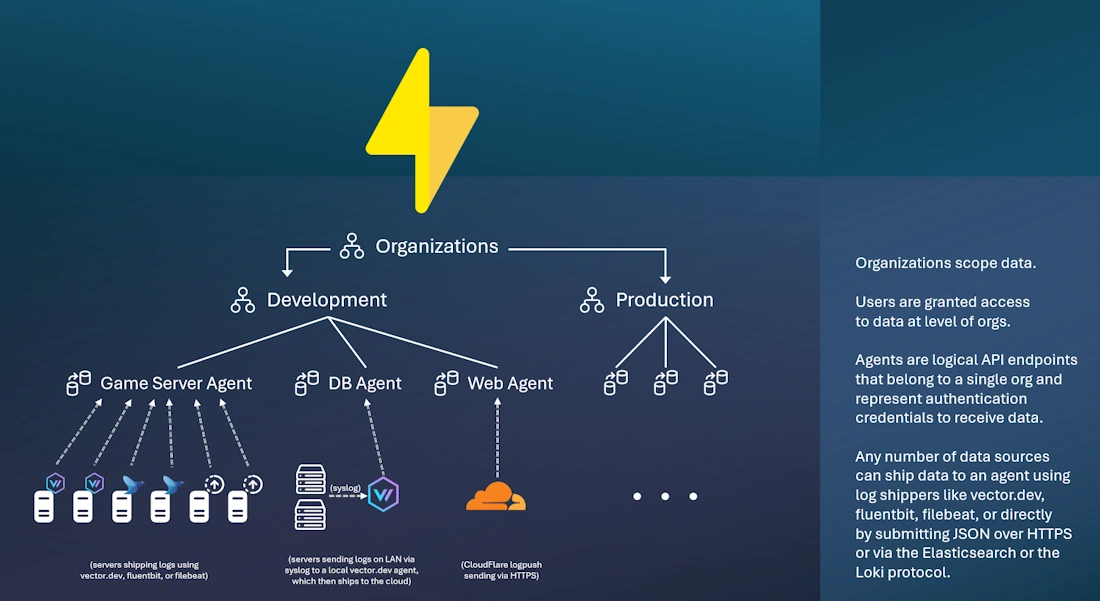
Ingest Anything
Open-source ingestion agents for files, Kubernetes, syslog, journald, Kafka, Docker, and more.
OpenTelemetry, vector.dev, filebeat, Logstash, Alloy.
Or ingest via REST or elasticsearch API.

Enterprise Ready
Data encrypted at rest and in-transit.
SSO in every plan. Role-based access control.
Optionally use your own Google cloud tenant.