Ingestion Overview
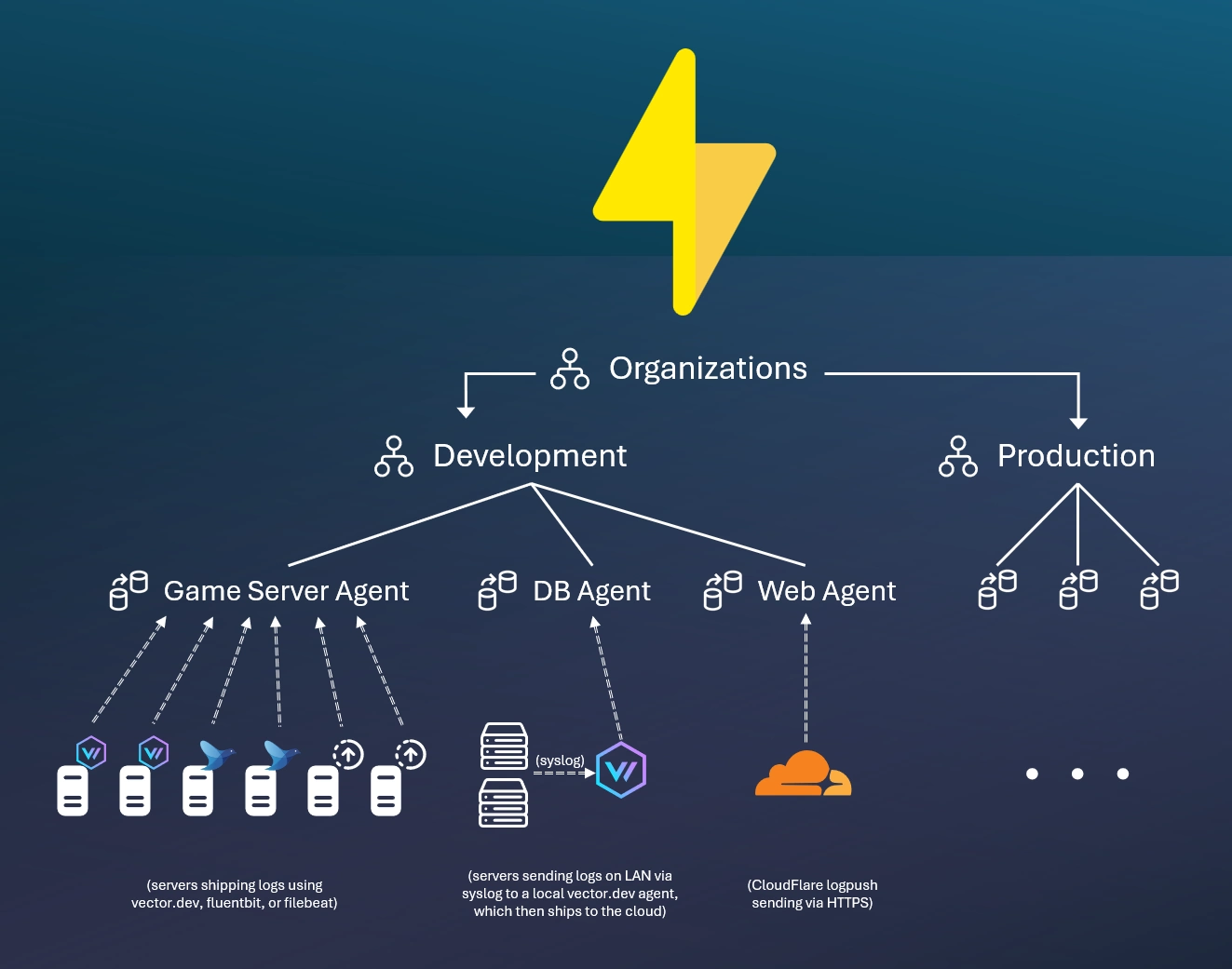
SparkLogs scopes your ingested data using the organization hierarchy. Users are granted access to some or all of this hierarchy.
Agents represent an authenticated endpoint to ingest data into a particular organization. Any number of devices and data sources can ship data to a single agent.
SparkLogs is OpenTelemetry-native: ship OTLP/HTTP logs directly using the OpenTelemetry Collector, Grafana Alloy, or any OTel SDK — see OTLP/HTTP for protocol details.
You can also use many other popular open source log shipping agents to send data to SparkLogs, including Vector, Fluent Bit, filebeat, and Logstash, or via our APIs: JSON data over HTTPS, Elasticsearch bulk indexing API, or Loki push API.
Most commonly, your application will write logs locally (e.g. to syslog or a local log file), and then you'll use a log forwarding agent to read the local logs and forward them to SparkLogs.
Refer to the tools & API guide for details on different log agents and APIs you can use to ingest data.
Intelligent Data Processing Engine
Ingested data from any source is then processed by AutoExtract
to automatically detect standard fields in message data (like message, timestamp, source, app,
and trace_id) and to automatically extract structured field information from your raw message text
(e.g., key/value pairs, JSON values in your log message, IP addresses and timestamps, etc.).
Data is further processed by AutoClassify to group similar messages and assign a pattern,
which can be used in pattern analysis to understand key trends in your data.
Many options are provided for timestamp management with an automatic config-free default behavior. The ingestion monitoring dashboard makes it easy to ensure ingestion is not lagging behind and all sources are sending data as expected.
Example Setup